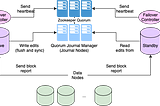
PinnedFault Tolerant 하둡 클러스터 구성이 페이지에서는 하둡(HDFS,YARN)의 HA아키텍쳐를 설명한다. Failover 탐지에 사용하는 Zookeeper도 어떻게 작동하는지 살펴본다. 설치 과정보다는 HA 구성을 하였을때 각 컴포넌트가 어떤 동작을 하는지를 중점으로 설명한다.Mar 3, 2021Mar 3, 2021
Published inNAVER CloudData Forest에서 Spark, Hive로 데이터 처리하기 Part.2지난 글(Part.1)에서는 네이버 클라우드 플랫폼 Data Forest에서 Zeppelin 앱을 생성하여 Spark Job과 Hive 쿼리를 실행해 봤습니다.Jul 20, 2021Jul 20, 2021
Published inNAVER CloudData Forest에서 Spark, Hive로 데이터 처리하기 Part.1네이버 클라우드 플랫폼 Data Forest는 빅데이터 처리를 위한 다양한 오픈소스 프레임워크를 제공합니다. 이번 페이지에서는 Data Forest에서 제공하는 Hadoop, Spark, Hive를 이용하여 데이터를 처리하고 저장하는 예제를…Jul 15, 2021Jul 15, 2021
Java, Scala 개발자를 위한 Apache Spark 소개유튜브 추천에 떠서 보게 된 영상인데, 많은 내용이 정리되는 느낌이어서 공유 할 겸 영상 내용을 요약해 보려고 한다. 슬라이드는 따로 제공되지 않아서 영상 링크를 첨부한다. 이번 페이지는 영상에서 소개되는 내용이 대부분임을 알려둔다.May 13, 2021May 13, 2021
HBase 알아보기 Part. 2앞에 Part1에서는 HBase가 어떻게 동작하는지에 중점을 두고 이야기했는데, 이번 페이지에서는 HBase를 언제 쓰면 좋을지에 대해 쓰려고 한다.Apr 21, 2021Apr 21, 2021
HBase 알아보기 Part 1이번에는 HBase가 어떤 성격의 데이터 저장소인지 알아본다. 그리고 HBase 내부에 데이터는 어떤식으로 저장되는지 그 데이터 모델과, 읽기/쓰기 작업이 일어나는 과정에 대해서도 정리해본다.Mar 24, 2021Mar 24, 2021
Published inNAVER CloudCloudHadoop에서 Hive UDF사용하기이 페이지에서는 Hive UDF(User Defined Function, 이하 UDF)를 구현하고, CloudHadoop에서 UDF를 사용하는 방법에 대해 설명합니다. Cloud Hadoop 1.2 클러스터가 이미생성되어 있다고 가정합니다.Nov 18, 2020Nov 18, 2020
Published inNAVER CloudFlume을사용해서 웹서버로그를HDFS 로 모으기이 페이지에서는 Flume에대해간략히설명하고, NCP Server에 있는 웹 서버 로그를 Cloud Hadoop의 HDFS에 저장하는 Flume Topology를 구성해봅니다.Sep 23, 2020Sep 23, 2020
Published inNAVER CloudZeppelin, Jupyter Notebook 서버 구성하여 Cloud Hadoop에 Spark Job 제출하기NCP Server에 Zeppelin, Jupyter Notebook 서버를 설치하고 Cloud Hadoop의 Spark와 연동하는 방법Jul 29, 2019Jul 29, 2019